
















I – Giới thiệu về kỹ thuật học máy trong bảo trì
Trong bài viết “Khoa học dữ liệu trong Bảo trì tài sản”, SpeedMaint đã mô tả sự khác biệt giữa bảo trì khắc phục, bảo trì phòng ngừa và bảo trì dự đoán. Kết luận rằng bảo trì dự đoán là kỹ thuật mạnh mẽ nhất mà các tổ chức cần tập trung vào và có thể mang lại nhiều giá trị nhất nếu thực hiện đúng cách. Tin tốt là với các kỹ thuật học máy, chúng ta có thể xây dựng các giải pháp cho các thách thức bảo trì dự đoán trong nhiều ngành công nghiệp không chỉ giới hạn ở một lĩnh vực hoặc loại trường hợp nhất định.
Chúng ta có thể giải quyết vấn đề bảo trì dự đoán bằng một trong các kỹ thuật sau:
- Học có giám sát — yêu cầu các sự kiện lỗi được gắn nhãn phải có trong tập dữ liệu
- Học không giám sát — chúng ta có thể sử dụng dữ liệu không chứa các sự kiện lỗi được gắn nhãn
II – Giải pháp bảo trì dự đoán toàn diện bằng học có giám sát
Yếu tố quan trọng nhất trong thành công của một hệ thống Bảo trì dự đoán dựa trên học máy mạnh mẽ và chính xác là chất lượng dữ liệu. Vì vậy, nếu chúng ta có đủ thông tin về các tình huống bảo trì trong dữ liệu đã thu thập, học máy có giám sát là cách để thực hiện. Ngoài ra, các vấn đề học máy có giám sát cũng có thể được chia thành các vấn đề hồi quy (khi đầu ra giả định các giá trị liên tục) và các vấn đề phân loại (khi đầu ra giả định các giá trị danh mục).
Ba nguồn dữ liệu bảo trì thiết yếu là cần thiết để xác định tính đủ điều kiện của một vấn đề đối với giải pháp Bảo trì dự đoán dựa trên học có giám sát bao gồm:
- Lịch sử lỗi của tài sản: Dữ liệu này giúp thuật toán có cơ hội học và đào tạo từ cả trạng thái hoạt động bình thường và khi xảy ra lỗi. Cần có đủ dữ liệu đào tạo với số lượng ví dụ phong phú trong cả hai trạng thái để mô hình học máy có thể hoạt động hiệu quả.
- Lịch sử chi tiết về bảo trì và sửa chữa: Mô hình cần biết tất cả các thành phần đã thay thế và các vấn đề đã được giải quyết. Điều này giúp mô hình hiểu rõ hơn về các yếu tố gây ra sự cố và cách khắc phục.
- Điều kiện máy móc, điều kiện hoạt động: Dữ liệu về điều kiện hoạt động của máy móc, chẳng hạn như nhiệt độ, độ rung và áp suất, là các yếu tố cần thiết để mô hình có thể dự đoán chính xác các sự cố tiềm ẩn.
III – Giải pháp Bảo trì dự đoán dựa trên học không có giám sát
Khi không có dữ liệu về lịch sử bảo trì, học máy không giám sát sẽ đóng vai trò như một nhà thám hiểm dữ liệu. Nó sẽ tự động tìm kiếm các mẫu, nhóm dữ liệu có liên quan để phát hiện các hoạt động bất thường của thiết bị, từ đó giúp chúng ta dự đoán và ngăn ngừa sự cố.
IV – Các kỹ thuật học máy có thể áp dụng trong bảo trì dự đoán
1. Cây quyết định (Decision trees)
Đây có lẽ là một trong những công cụ mạnh mẽ nhất để dự đoán và phân loại. Nó trông giống như một cấu trúc cây, mỗi nút bên trong biểu thị một phép thử trên một thuộc tính, kết quả của phép thử được biểu diễn bằng mỗi nhánh và mỗi nút lá (nút cuối) giữ một nhãn lớp.

Để xây dựng một cây, chúng ta cần chia một tập nguồn thành các tập con dựa trên phép thử giá trị thuộc tính. Đây là một quá trình có thể lặp lại cho mỗi tập con được suy ra theo cách đệ quy và được gọi là phân vùng đệ quy. Khi tập con tại một nút có cùng giá trị với mục tiêu khả dụng hoặc trong trường hợp khi việc chia tách không còn thêm giá trị vào dự báo nữa, thì quá trình đệ quy được coi là hoàn tất. Bạn không cần bất kỳ kiến thức miền hoặc thiết lập tham số nào để xây dựng bộ phân loại cây quyết định, do đó, nó phù hợp cho việc khám phá kiến thức thăm dò.
- Ưu điểm:
- Ít tốn công sức hơn đáng kể trong việc chuẩn bị dữ liệu trong giai đoạn tiền xử lý so với các thuật toán khác
- Không yêu cầu chuẩn hóa dữ liệu
- Không yêu cầu mở rộng dữ liệu
- Các giá trị bị thiếu không phải là vấn đề lớn hoặc gây gián đoạn khi xây dựng cây quyết định
- Rất trực quan và dễ hiểu, dễ giải thích cho các nhà phát triển và đối tác kinh doanh
- Nhược điểm:
- Sự bất ổn có thể xảy ra do sự thay đổi nhỏ nhất trong dữ liệu gây ra những thay đổi lớn trong cấu trúc cây quyết định
- Đôi khi cần tính toán phức tạp hơn nhiều so với các thuật toán hiện có khác
- Cây quyết định tương đối tốn kém hơn và mất nhiều thời gian hơn trong quá trình đào tạo
- Không phù hợp để giải quyết các vấn đề hồi quy hoặc dự đoán các giá trị liên tục
2. Máy vectơ hỗ trợ (Support Vector Machines – SVM)
Đây là mô hình phù hợp tuyệt vời cho các bài toán phân loại và hồi quy. Nó có thể giải quyết các bài toán tuyến tính, phi tuyến tính và hoạt động tốt cho nhiều bài toán thực tế khác.
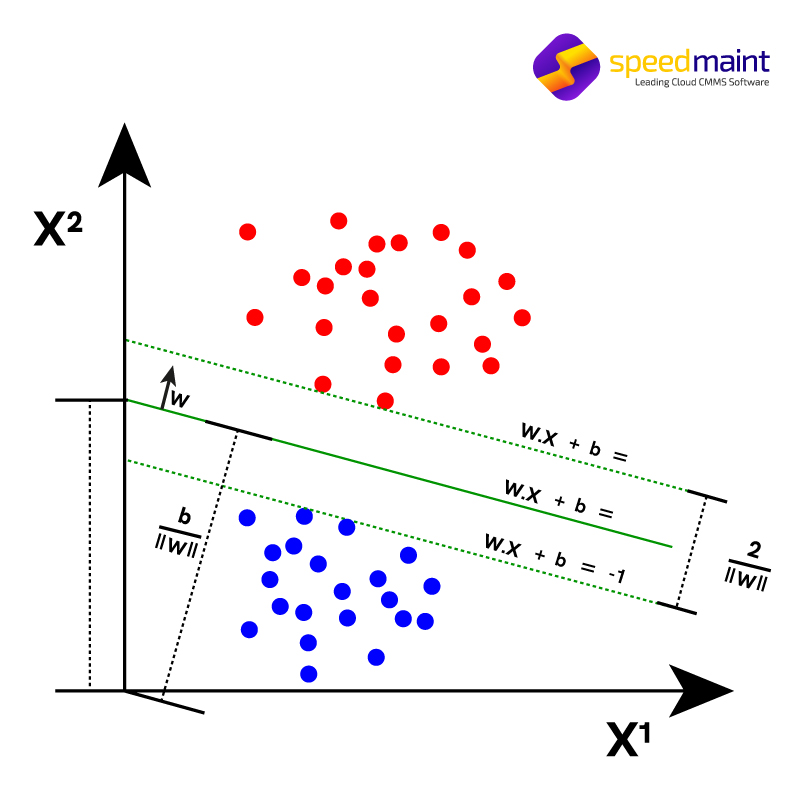
Ý tưởng chính của thuật toán này là tìm một siêu phẳng trong không gian N chiều (trong đó N biểu diễn số lượng các đặc điểm) phân loại rõ ràng các điểm dữ liệu. Trong số hai lớp điểm dữ liệu, có thể chọn rất nhiều siêu phẳng khả thi. Mục tiêu là tìm một siêu phẳng có biên độ tối đa hoặc khoảng cách tối đa giữa các điểm dữ liệu của cả hai lớp. Các điểm dữ liệu trong tương lai có thể được phân loại với độ tin cậy cao hơn khi khoảng cách biên độ được tối đa hóa.
- Ưu điểm:
- Hoạt động tốt ngay cả với dữ liệu không có cấu trúc và bán cấu trúc
- Có ít nguy cơ bị quá khớp
- Hoạt động tương đối tốt trong các tình huống có khoảng cách rõ ràng giữa các lớp
- Hiệu quả hơn nhiều trong không gian có nhiều chiều
- Rất hiệu quả trong các trường hợp mà số lượng chiều cao hơn số lượng mẫu
- Hiệu quả về bộ nhớ tương đối so với các thuật toán khác
- Nhược điểm:
- Không có lời giải thích xác suất cho việc phân loại
- Không có tiêu chuẩn nào để lựa chọn hàm hạt nhân
- Không phù hợp với các tập dữ liệu lớn
- Không hoạt động tốt khi dữ liệu có lượng nhiễu lớn và các lớp mục tiêu chồng chéo nhau
- Sẽ hoạt động kém trong các tình huống khi số lượng tính năng của mỗi điểm dữ liệu vượt quá số lượng mẫu dữ liệu đào tạo
3. Thuật toán K hàng xóm gần nhất (K-Nearest Neighbors – KNN)
Đây là thuật toán Học máy có giám sát có thể xử lý cả các vấn đề phân loại và hồi quy. Thuật toán KNN hoạt động theo cách các điểm dữ liệu tương tự ở gần nhau. Thuật toán tìm khoảng cách giữa một truy vấn và tất cả các ví dụ trong dữ liệu và chọn số lượng ví dụ đã chỉ định (K) gần nhất với truy vấn. Sau đó, thuật toán bỏ phiếu cho nhãn thường xuyên nhất, nếu chúng ta nói về phân loại. Đối với vấn đề hồi quy, giá trị trung bình của các nhãn đang được tính toán. Khi dữ liệu mới xuất hiện, nó đang được phân loại vào một trong các danh mục. Giả sử chúng ta có Lớp A, Lớp B và điểm dữ liệu mới chưa biết “?”. Điểm dữ liệu này đang được phân loại theo đa số phiếu bầu của các láng giềng và được gán cho lớp phổ biến nhất trong số K láng giềng gần nhất của nó, được đo bằng hàm khoảng cách.

- Ưu điểm:
- Không có thời gian đào tạo. KNN thường được gọi là Lazy Learner hoặc Instance-based learning. Vì thuật toán không học trong suốt thời gian đào tạo và không suy ra bất kỳ hàm phân biệt nào từ dữ liệu, chúng ta có thể coi là nó không có thời gian đào tạo. Nó có bộ lưu trữ các tập dữ liệu đào tạo và chỉ học khi đưa ra dự đoán theo thời gian thực. Tính năng này làm cho thuật toán này nhanh hơn các giải pháp thay thế khác yêu cầu đào tạo.
- Thêm dữ liệu mới liền mạch. Vì thuật toán KNN không cần đào tạo trước khi tạo dự đoán thực tế nên bạn có thể dễ dàng thêm dữ liệu mới và nó sẽ không ảnh hưởng đến độ chính xác tổng thể theo bất kỳ cách nào.
- Dễ triển khai. Để thực hiện, bạn chỉ cần hai tham số, giá trị K và hàm khoảng cách.
- Nhược điểm:
- Đây không phải là lựa chọn tốt nhất cho tập dữ liệu lớn vì chi phí cuối cùng để xác định khoảng cách giữa điểm mới và mỗi điểm hiện có sẽ rất lớn và làm giảm đáng kể mức hiệu suất của thuật toán.
- Không phải là lựa chọn tốt nhất cho nhiều chiều. Một lần nữa, với số lượng lớn chiều, thuật toán KNN sẽ không hoạt động tốt vì cần phải tính toán khoảng cách trong mỗi chiều.
- Yêu cầu tính năng mở rộng. Tính năng mở rộng, chuẩn hóa và chuẩn hóa là bắt buộc trước khi áp dụng thuật toán cho bất kỳ tập dữ liệu nào. Nếu không có động thái này, thuật toán KNN có nguy cơ đưa ra dự đoán sai vào cuối cùng.
- “K” trong thuật toán phải được xác định trước
- Thuật toán rất nhạy cảm với các tập dữ liệu không cân bằng
- Quá nhạy cảm với các giá trị bị thiếu, giá trị ngoại lai và dữ liệu nhiễu. Với thuật toán KNN, chúng ta không thể cho phép nhiễu trong tập dữ liệu. Tất cả các giá trị bị thiếu phải được thêm vào và các giá trị ngoại lai phải được xóa thủ công để thuật toán hoạt động bình thường.
V – Kết luận
Trong bài viết, chúng tôi đã nêu bật ba kỹ thuật Học máy phổ biến nhất để giải quyết thách thức Bảo trì dự đoán trong nhiều ngành công nghiệp khác nhau. Kết luận lại là, không có giải pháp tối ưu nào phù hợp với mọi tình huống. Một thuật toán phù hợp phải được lựa chọn cẩn thận và nghiêm ngặt, dựa trên vấn đề cụ thể về dữ liệu và vấn đề của doanh nghiệp, thời gian và ngân sách, cũng như mục tiêu kinh doanh. Mặc dù công nghệ Học máy cung cấp các kỹ thuật rất mạnh mẽ cho các thách thức Bảo trì dự đoán, nhưng chúng vẫn chưa hoàn hảo và có những hạn chế và nhược điểm riêng. Trong hầu hết các trường hợp, chúng ta cần dữ liệu có ý nghĩa được thu thập và xử lý đúng cách theo đúng cách để xây dựng giải pháp học máy phù hợp.
Thông tin liên hệ
Công ty TNHH MTV phần mềm SpeedMaint
Hotline: 0912 76 5656
Email: marketing@speedmaint.com
Website: https://speedmaint.com/
Fanpage: https://www.facebook.com/phanmemquanlybaotri/
Youtube: https://www.youtube.com/@phanmemquanlybaotrispeedmaint
Văn phòng Hà Nội: Khu văn phòng tầng 3, toà nhà CT1, Khu nhà ở Bộ Công An, đường Phạm Văn Đồng, phường Cổ Nhuế 2, quận Bắc Từ Liêm, Hà Nội
Văn Phòng HCM: Tầng 6 Tòa nhà Parami, 140 Bạch Đằng, P.2, Q. Tân Bình, TP. HCM




